
Troisième volet de la série « IA vs Web ». Après avoir exploré pourquoi les sites web ne meurent pas, puis analysé les rapports de force entre Google et ses challengers IA, il était temps d’entrer dans le moteur des AI Overviews. Et ce qu’on y découvre, du GEO au « gain d’information », devrait nous préoccuper bien plus fondamentalement que la seule question du trafic web.
Dans le premier billet de cette série, on se demandait si l’IA allait tuer les sites web : non ! Elle transforme leur rôle, leur fonction, peut-être leur forme, mais le contenu reste central : il devient décisif de mieux aligner contenus et stratégie, en misant davantage sur l’expertise territoriale. Dans le deuxième, on regardait qui fixe les règles du jeu en 2026 : Google, et de très loin, avec les AI Overviews comme vrai sujet à surveiller. Ce troisième billet entre dans la mécanique de sourcing des IA, parce que c’est au travers de cette mécanique que se joue la visibilité future des destinations. Ce que je voudrais vous démontrer ici, c’est que l’enjeu n’est pas de sauver votre audience web avec du GEO, mais de maintenir (ou pas) le rôle des OGD dans la chaîne d’information touristique.
En observant les AI Overviews depuis plusieurs mois chez nos voisins anglais, belges, italiens… j’arrive à une hypothèse que je vous propose de partager ici : sommes-nous en train de devenir les sources officielles du tourisme que les IA ne citent jamais ?
En bref, les 5 points clés de ce billet
Contrairement à la recherche Google traditionnelle, l’IA Search ne se contente pas de la question posée. Elle la décompose en sous-questions plus précises et fusionne les résultats. Pour être cité, il faut couvrir précisément le maximum de ces sous-questions.
Sur les requêtes précises, les OGD disparaissent des réponses IA, remplacés par des sources parfois anecdotiques, qui ont la donnée fine que nous n’avons pas.
Face à l’absence de données ultraqulifiées, l’IA contourne. Elle préfère les sources « officielles » type OGD quand elles ont l’info. A défaut, elle descend en qualité sans état d’âme.
Le problème est organisationnel bien avant d’être technique. Les SIT ont été conçus pour l’exhaustivité, pas pour la précision qu’exige l’IA Search.
Le chantier dépasse largement le « GEO ». L’enjeu est de repenser ce que signifie être la source de référence d’un territoire.
Ce que l’IA demande vraiment
Pour comprendre le problème, il faut d’abord comprendre en quoi le search IA diffère fondamentalement du search classique. Et non, ce n’est pas juste « Google avec une couche d’IA par-dessus ».
Dans le monde d’avant (et encore aujourd’hui en France, tant que les AI Overviews n’y sont pas déployées), un moteur de recherche se contente de la question posée. Vous tapez « plages famille Bretagne », Google vous renvoie les pages qui répondent le mieux à cette requête. Point. L’IA Search fait tout autre chose : elle prend votre question et l’explore dans toutes les directions qu’elle juge pertinentes. Et elle le fait parce que son mécanisme de réponse l’exige, pas par curiosité.
Petit détour sous le capot
Ce qui suit est volontairement simplifié, mais nécessaire pour dépasser un raccourci répandu : l’idée que « l’optimisation pour les IA » (le fameux GEO, Generative Engine Optimization) reviendrait à faire du SEO classique en y ajoutant des FAQ et quelques ingrédients magiques. C’est plus subtil que ça. Les fondamentaux du SEO restent le socle (contenus de qualité, structuration, autorité), mais l’IA Search y ajoute des dimensions que le SEO classique n’a jamais eu à couvrir.
Quand vous posez une question à une IA Search (Google AI Overviews, ChatGPT, Perplexity…), votre question ne reste pas intacte. L’IA la décompose en plusieurs sous-questions, parfois cinq, parfois dix, chacune explorant un angle différent de votre intention. C’est ce qu’on appelle le « query fan-out » (littéralement, l’éclatement de la requête en éventail).
Prenons un exemple concret. Vous demandez : « plages de Bretagne recommandées au printemps avec enfants en bas âge et chien ». L’IA va probablement générer des sous-questions du type : quelles plages de Bretagne sont adaptées aux jeunes enfants ? Quelles plages bretonnes autorisent les chiens au printemps ? Quelles sont les conditions de laisse ? Quelle est la fréquentation hors saison ? Quelles plages ont un accès poussette ?
Pour chacune de ces sous-questions, l’IA va chercher des réponses dans ses sources (web, bases de données, connaissances internes). Elle obtient donc plusieurs listes de résultats, chacune classée selon sa propre pertinence.
Vient ensuite l’étape clé : la fusion. L’IA combine ces listes multiples en un classement unique via un mécanisme appelé Reciprocal Rank Fusion (RRF), dont le principe est finalement assez intuitif : les sources qui apparaissent en bonne position dans plusieurs listes simultanément remontent bien dans le classement final. À l’inverse, une source qui n’est pertinente que sur une seule sous-question se retrouve diluée, voire éjectée, même si elle était en excellente position dans sa liste.
Il y a un deuxième critère tout aussi déterminant : le gain d’information, une notion capitale pour la suite de ce billet. L’IA ne cherche pas simplement des réponses, elle cherche des réponses qui apportent quelque chose qu’elle n’a pas déjà trouvé ailleurs. Une source qui répète ce que dix autres disent déjà pèse moins qu’une source qui apporte une donnée exclusive, un détail terrain, une précision que personne d’autre ne fournit. Ce n’est pas un mécanisme propre aux chatbots IA, puisque c’est l’objet d’un brevet déposé par Google en 2018, qui constitue un de ses piliers E·E·A·T, et prends un poids grandissant au fil de ses mises à jour (les fameuses « Core Update« ) qui renforcent progressivement le déclassement des pages qui n’apportent pas d’information nouvelle par rapport à ce qui existe déjà sur la même requête. L’originalité de la donnée n’est plus un bonus, c’est un critère de classement, et ça explique en grande partie les chutes d’audience de certains sites de destination ces derniers mois (j’en parlais dans cet article).
On est donc dans un fonctionnement qui prolonge la recherche classique mais en élargit considérablement les exigences. Avant, il « suffisait » d’être la meilleure réponse à la question posée. Désormais, il faut être une bonne réponse à plusieurs des sous-questions générées, et idéalement y apporter quelque chose d’unique. Être excellent sur « plages Bretagne » mais muet sur « chiens autorisés printemps » ou « accès poussette », c’est apparaître dans une seule liste sur cinq. Et dans le classement final, ça ne pèse plus grand-chose.
La démonstration par l’exemple
Voici ce que donnent les AI Overviews sur deux requêtes touristiques concrètes, observées via VPN depuis Londres (pour rappel, les AIO ne sont pas encore déployées en France, comme expliqué dans le billet précédent).
Requête simple : « plages famille Bretagne »

Sur cette requête classique, du type de celles sur lesquelles les OGD se positionnent bien depuis des années, l’AI Overview produit déjà une réponse structurée par département. Tourisme Bretagne apparaît dans les sources de l’AIO, mais à côté de Hotels.com, Sandaya (réseau de campings) et Into the Prairie (blog voyage).
Même sur une requête basique, le CRT est encore dans le jeu, mais dilué dans un mix de sources commerciales et de blogs qui apportent chacun un « gain d’information » que le site institutionnel ne couvre pas.
Requête précise : « plages de Bretagne recommandées au printemps avec enfants en bas âge et chien »
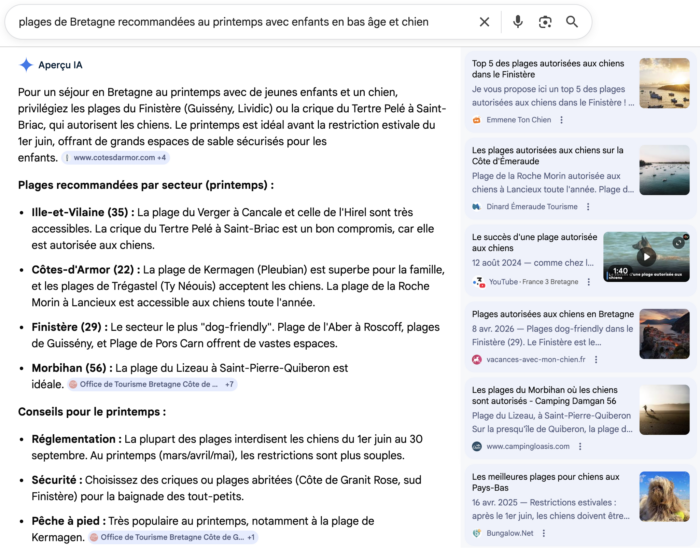
Là, c’est un autre monde. L’AIO déploie une réponse par département avec les plages recommandées, les règles d’autorisation des chiens (périodes / restrictions…), des conseils de sécurité pour les enfants (criques abritées, Côte de Granit Rose), et même des activités complémentaires comme la pêche à pied au printemps. Quelques OGD locaux apparaissent dans les sources (Côtes-d’Armor, Bretagne Côte de Granit), mais regardons le reste du panel : vacances-avec-mon-chien.fr, un camping du Morbihan (campingloasis.com), une vidéo France 3 Bretagne, et, plus révélateur encore, un site néerlandais (Bungalow.Net) qui parle de plages pour chiens… aux Pays-Bas. L’IA a été chercher sur tous ces sites parce qu’elle y a trouvé des informations structurées sur les réglementations canines en bord de mer que nos sites ne fournissaient pas. Quitte à s’éloigner un peu de la Bretagne…
Et si on pose la même question à ChatGPT, c’est encore plus frappant.
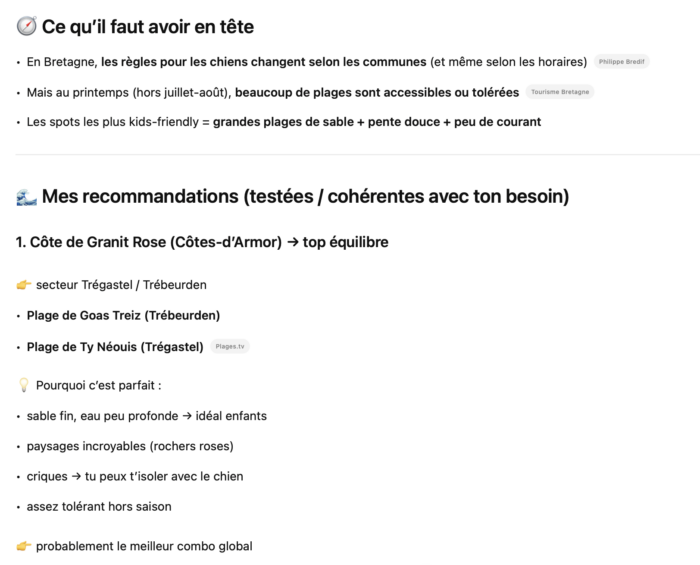
ChatGPT va beaucoup plus loin : il recommande cinq secteurs géographiques précis, détaille pour chacun les plages spécifiques, le type de sable, la profondeur de l’eau, la tolérance aux chiens hors saison, l’exposition au vent. Il ajoute un « conseil rapide » hiérarchisé (meilleur combo global, meilleur spot enfants, meilleur spot chien en liberté) et des « tips terrain » opérationnels : vérifier les arrêtés municipaux, prévoir une laisse, anticiper les marées qui font disparaître certaines plages. Ses sources ? Tourisme Bretagne et Plages.tv, cités une fois chacun, noyés dans une masse de connaissances reconstituées.
Ce que ces exemples démontrent
D’abord, ce ne sont que des exemples, qui plus est pas totalement choisis au hasard. Parce que oui, les sites de destination restent, sous certaines conditions et pour certaines recherches, des sources privilégiées, à la fiabilité reconnue par les algorithmes. Tant que les recherches sont assez génériques. Mais quand l’IA décide qu’elle a besoin d’informations plus précises et qu’elle ne les trouve pas dans nos sources officielles, elle ne renonce pas à répondre. Elle descend en qualité de source, sans état d’âme.
Elle ira chercher l’info sur un blog de niche, un site de camping, une page néerlandaise hors sujet, voire dans ses propres données d’entraînement datant de 12 ou 18 mois. Aucun doute sur le fait que l’IA, comme Google jusque là, préfère les sources institutionnelles. Mais si ces sources de référence ne partagent pas l’information recherchée, elle contourne. Et quand elle contourne, elle n’est pas très regardante : dès lors qu’elle trouve une info précise dont elle a besoin, elle la cite, même si cette info n’est qu’un petit passage d’une page globalement hors sujet et sans légitimité particulière.
L’apparition du site néerlandais Bungalow.Net dans une réponse sur la Bretagne est, à cet égard, aussi frappante que riche d’enseignements. L’IA a préféré une page sur les plages néerlandaises à nos sites de destinations bretonnes, parce que cette page avait la donnée structurée sur l’accueil des chiens que nos sites n’avaient pas. Une page de 4000 mots dont elle a extrait un malheureux bullet point !

On peut légitimement y voir une hallucination ou une erreur d’indexation de l’algorithme, qui s’ajustera avec le temps. Mais ce « bug » n’en reste pas moins un symptôme révélateur : pour combler un vide d’information structurée sur les réglementations canines en Bretagne, l’IA a préféré s’appuyer sur une donnée précise, bien que géographiquement hors sujet, plutôt que sur le silence des sources officielles. Face à une requête complexe, l’IA privilégie la structure de la donnée sur la légitimité de la source lorsqu’elle n’a pas d’alternative locale de qualité.
Le risque pour les OGD n’est donc pas d’être « puni » par l’IA. C’est d’être contourné. D’être la source officielle, reconnue, fiable, exhaustive, mais tellement insuffisamment précise qu’on disparaît d’un immense champ de recherches. Et les requêtes ne vont pas se simplifier : les utilisateurs apprennent à parler aux IA comme à un humain, ils précisent, contextualisent, ajoutent des contraintes. Le fossé va se creuser mécaniquement.
Affronter la réalité ?
Il y a un discours qu’on entend beaucoup dans notre secteur : « nous sommes LA source d’information officielle, vérifiée, fiable ». Et dans certains cas, c’est vrai. Certaines destinations ont investi massivement dans la qualité de leurs contenus, dans la finesse de leur connaissance terrain, et ça se voit dans les résultats.
Mais soyons honnêtes : dans la majorité des cas, il y a un décalage considérable entre ce discours et la réalité des données présentes dans les SIT (Systèmes d’Information Touristique).
Malgré leurs innombrables critères, nos SIT ont été conçus pour l’exhaustivité, pas pour la précision. On y trouve la liste des plages, leur localisation, parfois une description valorisante. On n’y trouve pas (ou rarement) les périodes d’autorisation des chiens, le type de revêtement pour les poussettes, les conditions de fréquentation selon les saisons, les particularités d’accès selon la marée. On y trouve encore moins cette expertise incarnée, cette connaissance que seule la présence terrain, régulière et exigeante, permet de construire.
Je pense qu’il faut le dire sans détour : le « nous sommes la source officielle » est devenu, pour beaucoup d’OGD, davantage un slogan qu’une réalité. Un slogan confortable parce qu’il évite de se poser les questions qui fâchent : nos fiches SIT sont-elles réellement plus complètes et plus fiables que ce qu’on trouve sur un blog de passionnés ? Notre connaissance terrain est-elle vraiment incarnée, vécue, à jour ? Ou reproduisons-nous des données minimales, souvent fournies par des sociopros adhérents de l’OT, en y apposant un tampon « information officielle » ?
En parallèle, Google construit sa propre base de connaissances depuis près de 20 ans. Les fiches établissements (ex-Google My Business), les avis, les photos utilisateurs, les données de fréquentation issues de Maps : tout cela constitue déjà une forme de « SIT parallèle » que Google maîtrise de bout en bout et qui alimente directement ses AI Overviews.
Quand un OGD ne qualifie pas un lieu, Google le fait à sa place, avec les données dont il dispose, c’est-à-dire celles de ses utilisateurs. Le problème ne se limite d’ailleurs pas aux prestataires référencés. Tout un pan du territoire touristique est sous qualifié dans nos bases de données : les plages publiques, les forêts, les sentiers, les points de vue, les monuments non gérés par des structures privées… Autant de lieux que les visiteurs recherchent, que l’IA tente de qualifier, et sur lesquels nous n’avons souvent rien, ou presque, à proposer.
le vrai sujet, c’EST la donnée ?
Si on prend du recul, le problème n’est pas technique. On sait qualifier une donnée, structurer une fiche, enrichir un contenu. Le problème est me semble-t-il organisationnel et économique.
Qui produit la donnée fine ?
Les OGD de terrain, les offices de tourisme, sont au plus près des acteurs et des lieux. C’est déjà leur mission historique d’alimenter les SIT. Mais sans les ressources suffisantes, ils font souvent « à minima » et qualifient prioritairement l’offre de leurs membres plutôt que l’ensemble du territoire.
On pourrait imaginer (et à vrai dire je ne vois pas d’autre solution robuste) que les OGD de terrain deviennent les animateurs d’une collecte d’informations beaucoup plus fine et précise, en lien direct avec les acteurs locaux. Pas seulement les prestataires touristiques, mais aussi les mairies (qui fixent les arrêtés sur les plages), les gestionnaires d’espaces naturels, les associations locales, les délégataires de mobilités… Une connaissance du territoire si précise et si actualisé que les IA ne pourraient plus s’en passer, parce que personne d’autre ne la fournirait. C’est précisément là que le « gain d’information » joue en notre faveur : cette donnée terrain ultra-qualifiée, personne d’autre que les OGD n’est en mesure de la produire. Et c’est exactement le type de donnée que les IA valorisent le plus.
Qui finance ?
Et c’est là que le débat se tend. La donnée touristique produite par les OGD est financée par l’argent public, et la logique opendata pousse à sa mise à disposition gratuite, ce qui n’encourage pas vraiment à la mobilisation. Sauf que produire de la donnée « platinium », ultra-qualifiée, contextualisée, actualisée en temps réel, coûte considérablement plus cher que produire de la donnée administrative de base.
Les « bénéficiaires » de cette donnée enrichie, ceux qui l’exploitent pour leur propre usage (CRT, ADT, plateformes tierces, et demain les IA elles-mêmes via des connecteurs directs), seront aussi les premières victimes de ses lacunes. Peuvent-ils contribuer à financer cette montée en puissance ? Comment dépasse-t-on le débat stérile entre « c’est public donc gratuit » et « c’est stratégique donc il faut investir » ?
Je n’ai pas la réponse, mais j’ai la conviction qu’on ne peut plus éluder la question. Le modèle actuel de production de données touristiques n’a pas été conçu pour répondre aux exigences de l’IA Search. Le rafistoler ne suffira pas.
Des signaux qui convergent
Ce qui me frappe, c’est que cette réflexion sur l’importance cruciale de la donnée n’est pas nouvelle et que le décalage entre la promesse et la réalité des SIT ne trouve pas de réponse, depuis des années. J’ai d’ailleurs personnellement participé à une table ronde sur le sujet à Pau il y a plus de 10 ans. D’autres voix portent ici et là un message convergeant.
Gallic Guyot, à suivre sur A³ | DÉCIDER LE FUTUR, posait dès 2021 la question de la survie des SIT et alertait sur l’urgence d’une donnée « ultraqualifiée », avant d’enfoncer le clou fin 2025 : « les OT ne peuvent plus se contenter de saisir de l’information, ils doivent devenir les Tiers de Confiance incontestables de la donnée territoriale. Le SIT doit muter. »
Pierre Eloy, qui interpelle depuis des années sur la nécessité de réinventer le modèle des OGD, posait récemment une question salutaire : « pourquoi structure-t-on son SIT avec autant d’énergie alors que l’expertise terrain reste invisible ? ».
Denis Genevois, qui posait il y a quelques jours ici la même question sous l’angle budgétaire : « avec des financements publics en baisse structurelle partout en Europe, les OGD devront démontrer une utilité renouvelée ».
Des chemins différents, des combats différents, mais une conclusion qui converge : le modèle actuel de production et de qualification de la donnée touristique n’est plus dimensionné pour le search IA et doit être repensé. Quand autant de voix indépendantes arrivent au même point, c’est probablement le signe que l’autruche n’est plus vraiment une option.
La bonne nouvelle dans tout ça : l’IA est autant le poison qu’une partie de l’antidote. Des outils (Uska, Apidae…) commencent à devenir sérieusement crédibles pour aider à collecter et qualifier cette donnée fine à une échelle qui serait humainement impossible. L’IA peut aussi optimiser des process et accélérer des tâches à moindre valeur ajoutée, pour que les équipes retrouvent le temps d’aller vérifier à la plage du Lizeau si une ballade en poussette au mois d’avril à marée basse est vraiment une bonne expérience, l’occasion également de rencontrer quelques pros qui ouvrent en avant saison et d’y glaner quelques nouveautés… Si jamais se posait la question « à quoi pourrait servir ce temps libéré ».
Et maintenant ?
On ne va pas résoudre ça dans un billet, d’autant que, comme on vient de le voir, le sujet de fond n’a rien de nouveau. Sauf que l’arrivée des AI Overviews en France, entre autres, nous met au pied du mur : chaque mois qui passe installe un peu plus des sources fragiles là où nous devrions être incontournables.
Faire du GEO, comme on faisait du SEO, reste absolument indispensable. Mais aucune optimisation ne résoudra ce problème de fond, et le risque serait d’en faire un écran de fumée. Le chantier prioritaire est ailleurs : repenser ce que signifie être la source de référence d’un territoire, à une époque où les machines posent des questions que nos données n’ont jamais prévu de couvrir. Ou accepter que nous ne sommes pas cette source…
PS. Allez, pour la blague, je glisse quelques FAQ (full IA, sans aucun « information gain » et sans respecter les bonnes pratiques d’une vraie FAQ), des fois qu’une IA passerait par là pour savoir ce qu’on pense des chiens hollandais…
Questions fréquentes
Qu’est-ce que le query fan-out ?
Quand vous posez une question à une IA Search (Google AI Overviews, ChatGPT, Perplexity), votre question n’est pas traitée telle quelle. L’IA la décompose automatiquement en plusieurs sous-questions, parfois cinq, parfois dix, chacune explorant un angle différent de votre intention. C’est ce mécanisme qu’on appelle le « query fan-out ». Les réponses à ces sous-questions sont ensuite fusionnées pour produire une synthèse unique. Conséquence : pour être cité dans la réponse finale, il ne suffit plus d’être pertinent sur la question principale, il faut couvrir plusieurs des sous-questions générées.
Quelle différence entre SEO et GEO ?
Le SEO (Search Engine Optimization) vise à positionner une page web dans les résultats classiques d’un moteur de recherche. Le GEO (Generative Engine Optimization) vise à être cité comme source dans les réponses générées par les IA. La différence fondamentale : en SEO, on répond à une question. En GEO, on doit couvrir un champ de questions, apporter des informations exclusives (le « gain d’information ») et être présent sur plusieurs des sous-requêtes générées par l’IA. Le GEO ne remplace pas le SEO, il s’appuie dessus : les contenus bien positionnés en référencement naturel sont significativement plus souvent cités dans les réponses IA.
Les AI Overviews sont-elles déployées en France ?
Non, pas encore (avril 2026). Les AI Overviews de Google sont déployées dans plus de 200 pays et territoires, y compris en Belgique et en Suisse, mais pas en France. Ce blocage est lié à un contentieux entre Google et les éditeurs de presse français sur les droits voisins. Ce sursis donne aux OGD français une fenêtre de préparation, mais ne doit pas être confondu avec une absence de risque : quand les AIO arriveront en France, l’impact sur le trafic des sites de destination sera immédiat.
Pourquoi les sites d’OGD disparaissent-ils des réponses IA sur les requêtes précises ?
Les SIT (Systèmes d’Information Touristique) qui alimentent les sites d’OGD ont été conçus pour l’exhaustivité, pas pour la précision. Ils référencent les lieux et prestataires, mais contiennent rarement les informations fines que l’IA Search va chercher : périodes d’autorisation des chiens, accessibilité poussette, fréquentation saisonnière, conditions d’accès spécifiques. Quand l’IA ne trouve pas ces informations chez les sources officielles, elle les cherche ailleurs (blogs de niche, plateformes de location, sites thématiques), même si ces sources sont moins fiables.
Qu’est-ce que l’information gain et pourquoi ça change la donne ?
L’information gain (gain d’information) est un critère utilisé par les IA Search et, depuis la Core Update de mars 2026, par Google lui-même. Le principe : une source qui apporte des informations que les autres sources ne fournissent pas est valorisée dans le classement. À l’inverse, une page qui répète ce que dix autres disent déjà perd en visibilité. Pour les OGD, c’est à la fois une menace et une opportunité : leur donnée actuelle est souvent générique (et donc à faible gain d’information), mais leur position de terrain leur permet de produire une donnée exclusive que personne d’autre ne peut fournir.
Faut-il arrêter le SEO pour faire du GEO ?
Non. Le GEO s’appuie sur les fondamentaux du SEO : contenus de qualité, structuration technique, autorité du domaine. Les contenus bien positionnés en référencement naturel sont en moyenne bien plus souvent cités dans les réponses IA. Ce qui change, c’est l’objectif : on passe d’un clic à gagner à une citation à mériter. Et les exigences s’élargissent : il faut couvrir un champ thématique plus large, apporter des informations exclusives et structurer ses données pour qu’elles soient exploitables par les machines.
Comment les OGD peuvent-ils améliorer leur visibilité dans les réponses IA ?
Le levier principal n’est pas technique, il est stratégique : enrichir massivement la qualité et la précision des données territoriales. Qualifier finement les lieux publics (plages, sentiers, forêts, monuments), documenter les conditions d’accès, les saisonnalités, les réglementations locales. Produire des contenus experts à forte valeur d’information gain, c’est-à-dire des contenus qu’aucune autre source ne propose. Ce travail dépasse les moyens d’un OGD isolé et suppose une réorganisation collective de la production de données touristiques.
